Intro
Kafka 採用分散式架構實現了高性能的 Logging 與 Messaging 功能。與 RabbitMQ 相比,Kafka 採用 Pull Model,允許 Consumer 根據自身處理能力主動拉取資料,且支援訊息重覆拉取與留存 (Retention),這使得資料不僅能被即時處理,還具備了事後回溯與批次分析的能力。

分散式架構與演進
在早期的 Apache Kafka 架構中,ZooKeeper 扮演著關鍵的「外部大腦」角色,負責管理 Cluster 的元數據(Metadata)、選舉 Controller 以及記錄 Partition 的狀態。然而,隨著數據量級的提升,這種「雙系統」架構產生了元數據同步延遲與維護複雜度的瓶頸。
為了優化效能,Kafka 自 2.8 版本引入了 KRaft (Kafka Raft) 模式,並在 3.x 版本後趨於成熟。KRaft 的核心在於將元數據管理直接整合進 Kafka 內部,讓 Broker 自身就能透過 Raft 共識演算法來達成集群一致性。
轉向 KRaft 的三大優勢:
-
擴展性提升: 消除 ZooKeeper 的寫入限制,支持數百萬個 Partition。
-
故障恢復極速: 當 Controller 發生切換時,元數據已在內存中,無需從 ZooKeeper 重新加載,大幅縮短停機時間。
-
運維簡化: 不再需要額外維護 ZooKeeper 集群,簡化了部署架構與安全性設定。
主要 API
- Producer API: 推送資料角色使用
- Consumer API: 拉取資料角色使用 (Kafka 為 Pull Model)。實作上是各語言透過 SDK 反覆呼叫 consume 請求,consumer 會向 broker request messages。
- Connect API: 一般指 Kafka Connect 中的外部 Storage connector plugin 使用。
- Admin API: Kafka admin 角色使用。可以設定 Topic, partition 等。
- Streams API:負責「加工」數據。它同時具備 Consumer 與 Producer 的特性,專門處理即時的流運算(如:過濾、聚合、Windowing Join)。
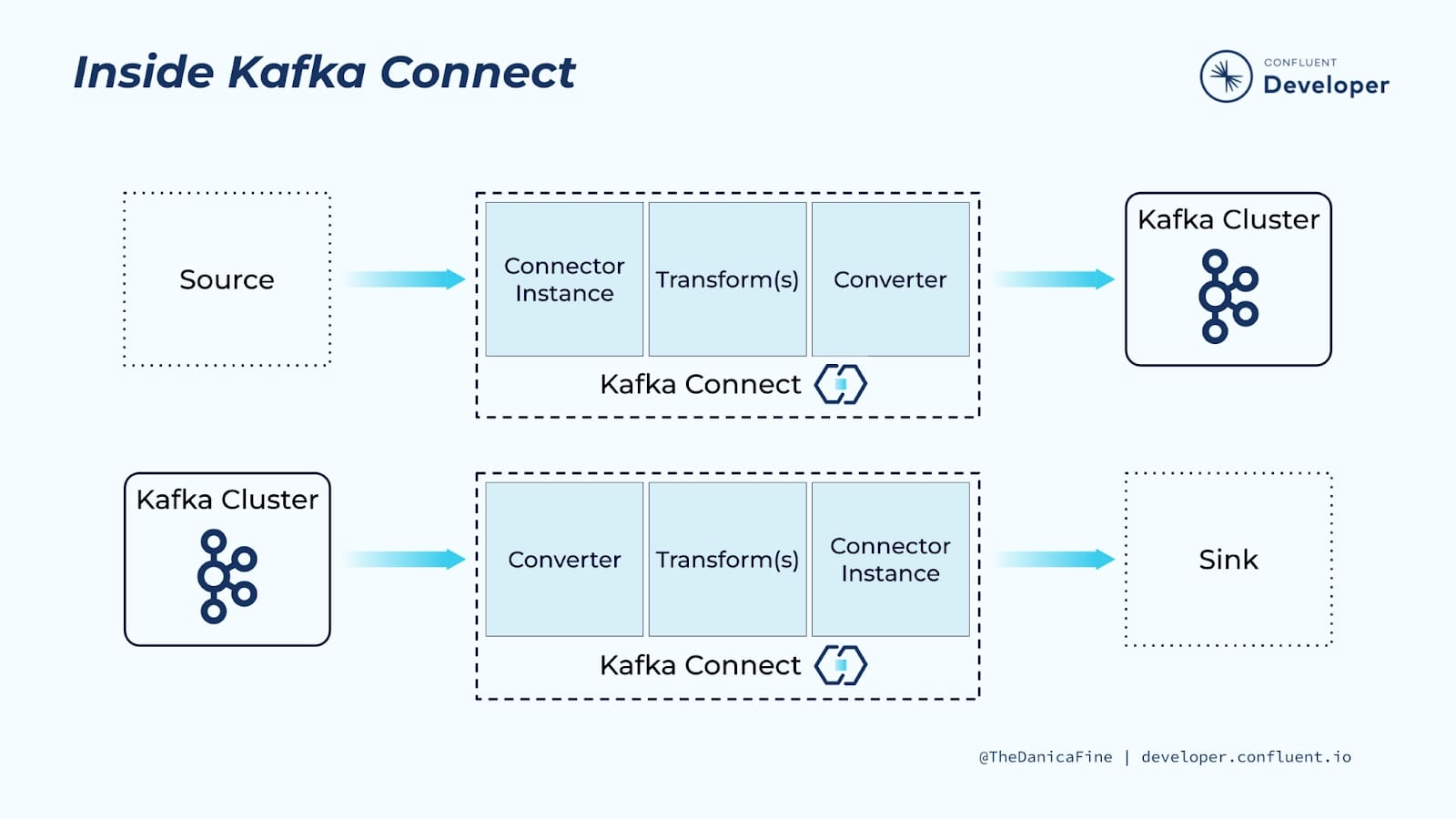
Kafka Connect & Connector
Kafka Connect 為獨立 component,通常與 Kafka broker 分開搭建 cluster。Kafka Connect 可以安裝不同的外部 Storage connector plugin 來做設定連接,設定檔也包含對哪個 topic 做 pull/push,透過啟動對應的 Kafka Connect worker 來執行。
例如搭建 Kafka Connect,安裝設定 S3 connector plugin 並啟動 Connect worker 來連結到 Kafka broker 處理部分 Topic 資料,若同時設有 pull/push 則架構如: S3 -> Kafka Connect -> Kafka -> Kafka Connect -> S3。
數據模型:Topic 與 Partition
在 Kafka 中,數據是以 Topic 為單位進行邏輯分類,並透過 Partition 實現物理上的分散式存儲。
-
Topic (邏輯分類)
定義:訊息的類別名稱(例如 order-events 或 payment-logs)。
多訂閱者:一個 Topic 可以同時被多個不同的 Consumer Group 訂閱,且彼此處理進度(Offset)互不干擾。 -
Partition (物理分片)
水平擴展:一個 Topic 可以拆分為多個 Partition,分散在不同的 Broker 上。這讓單個 Topic 的吞吐量不受單機磁碟或網路 I/O 的限制。
併行單位:在同一個 Consumer Group 中,一個 Partition 同時只能由一個 Consumer 消費。因此,Partition 的數量決定了該 Topic 的最大併行處理能力。 -
順序性保障 (Ordering)
局部有序:Kafka 僅保證單個 Partition 內部的訊息順序(按 Offset 遞增)。
Key-based Routing:若業務要求特定資料(如同一訂單的所有狀態變更)必須有序處理,發送時需指定相同的 Message Key,確保該 Key 的所有訊息都會進入同一個 Partition。 -
高可用性:副本機制 (Replication)
每個 Partition 都有多個副本(Replicas),並分為兩種角色:
Leader:負責所有的讀寫請求,是效能的核心。
Follower:僅從 Leader 同步數據,作為冗餘備份。

(Reference: https://www.lydtechconsulting.com/blog/kafka-message-keys)
ISR (In-Sync Replicas):與 Leader 保持同步的副本集合。當 Leader 故障時,系統會從 ISR 中選出新 Leader,配合 ACK 機制 確保金融級的數據不丟失。
ACK 機制
ACK (Acknowledgment) 確保分散式系統中的一致性,分為發送端與接收端兩個維度:
Producer 端的 acks 配置
-
acks=0:發出即完成,不等待回應(高吞吐、高風險)。
-
acks=1 (Default):Leader 寫入成功即回應(折衷方案)。
-
acks=all (-1):ISR (In-Sync Replicas) 全數同步才回應(金融級可靠性)。
Consumer 端的 Offset 提交
Consumer 透過提交 Offset 記錄消費進度。在預設的自動提交模式下,會定期批次更新處理位移。
若 Consumer 兩次 poll 的間隔超過設定時間(或心跳中斷),Broker 會判定該 Consumer 失聯並觸發 Rebalance。
Rebalance
Rebalance 是 Kafka Consumer Group 的自動負載均衡機制。當群組成員變動(如新增/移除 Consumer)或處理邏輯超時(超過 max.poll.interval.ms)時,Broker 會介入並重新指派每個 Consumer 負責的分區。
-
進度凍結與切換:
當 Rebalance 觸發,舊的 Consumer 會立即停止讀取。新的 Consumer 接手該 Partition 後,會查詢內部系統 Topic __consumer_offsets,從該群組最後一次成功提交 (Commit) 的位移處繼續讀取。 -
重複消費的風險:
由於 Kafka 採用的不是單筆訊息的確認,而是位移提交。若 Consumer A 處理了 100 筆資料,但在提交這批 Offset 前就發生了 Rebalance,該 Partition 被分配給 Consumer B 後,B 會從上一次已提交的起點重新拉取。
Idempotency (冪等性)
在分散式系統中,網路抖動或服務重啟(Rebalance)常導致訊息重發。為了達到 Exactly-Once (精準一次) 的處理效果,可以從發送端與接收端建立雙層防禦:
發送端:Idempotent Producer (進場防護)
在 Producer 設定 enable.idempotence=true。Kafka 會自動過濾因網路 ACK 遺失而導致的重覆寫入。
-
原理:Broker 會紀錄每個 Producer 的身分 (PID) 與訊息流水號 (Sequence Number)。
-
判定:若收到已存在或序號較小的訊息,Broker 將自動丟棄該請求,確保 Kafka Log 內數據的純淨與順序性。
-
價值:防止數據在源頭被污染,並在 Retry 過程中維持嚴格的訊息順序。
接收端:Consumer Idempotency (最後防線)
即便 Log 是乾淨的,Consumer 仍可能因處理完畢後、提交 Offset 前發生 Rebalance,導致同一筆資料被再次拉取。因此,Consumer 必須具備防重邏輯。
實作策略:
-
資料庫唯一約束 (Unique Key):利用交易 ID 或 Order ID 作為 PK/UK,重覆寫入時由 DB 擋下。
-
狀態檢查 (Status Check):執行前先檢查該筆交易是否已是「完成」狀態。
-
分散式鎖 (Distributed Lock):使用 Redis SETNX 標記正在處理中的訊息。
為什麼發送與接收端都重要?
Producer 冪等是「品質」:確保進到倉庫(Kafka)的貨物沒有重覆,減少下游 10 個 Consumer 都要重複查 DB 的負擔與 I/O 損耗。
Consumer 冪等是「義務」:解決業務邏輯層的重啟與失敗重試,是系統最終一致性的絕對保障。
結論:在高併發場景中,應採取「深度防禦」策略:由 Producer 確保數據源頭乾淨,由 Consumer 守住業務邏輯的最後一關。